De graden van vrijheid in statistieken zijn ze het aantal onafhankelijke componenten van een willekeurige vector. Als de vector heeft n componenten en er zijn p lineaire vergelijkingen die hun componenten relateren, dan is de graad van vrijheid is n-p.
Het concept van graden van vrijheid Het komt ook voor in de theoretische mechanica, waar ze ongeveer gelijk zijn aan de dimensie van de ruimte waarin het deeltje beweegt, minus het aantal bindingen..
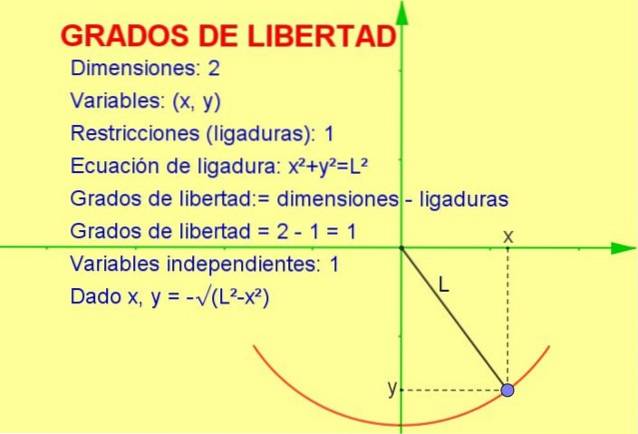
Dit artikel bespreekt het concept van vrijheidsgraden dat op statistiek wordt toegepast, maar een mechanisch voorbeeld is gemakkelijker in geometrische vorm te visualiseren.
Artikel index
Afhankelijk van de context waarin het wordt toegepast, kan de manier om het aantal vrijheidsgraden te berekenen variëren, maar het achterliggende idee is altijd hetzelfde: totale afmetingen minus aantal beperkingen.
Laten we eens kijken naar een oscillerend deeltje dat is vastgemaakt aan een touwtje (een slinger) dat beweegt in het verticale x-y-vlak (2 dimensies). Het deeltje wordt echter gedwongen te bewegen over de omtrek van de straal die gelijk is aan de lengte van het akkoord.
Omdat het deeltje alleen op die curve kan bewegen, is het aantal graden van vrijheid is 1. Dit is te zien in figuur 1.
De manier om het aantal vrijheidsgraden te berekenen is door het verschil van het aantal dimensies minus het aantal beperkingen te nemen:
vrijheidsgraden: = 2 (afmetingen) - 1 (ligatuur) = 1
Een andere verklaring waarmee we tot het resultaat kunnen komen, is de volgende:
-We weten dat de positie in twee dimensies wordt weergegeven door een coördinatenpunt (x, y).
-Maar aangezien het punt moet voldoen aan de vergelijking van de omtrek (xtwee + Ytwee = Ltwee) voor een gegeven waarde van de variabele x, wordt de variabele y bepaald door de genoemde vergelijking of beperking.
Dus slechts één van de variabelen is onafhankelijk en het systeem heeft één (1) vrijheidsgraad.
Stel dat de vector om te illustreren wat het concept betekent
X = (x1, Xtwee,..., xn
Wat vertegenwoordigt de steekproef van n normaal verdeelde willekeurige waarden. In dit geval de willekeurige vector X hebben n onafhankelijke componenten en daarom wordt gezegd dat X hebben n vrijheidsgraden.
Laten we nu de vector bouwen r van afval
r = (x1 -
Waar
Dus de som
(X1 -
Het is een vergelijking die een beperking (of binding) voorstelt aan de elementen van de vector r van de residuen, aangezien als n-1 componenten van de vector bekend zijn r, de beperkingsvergelijking bepaalt de onbekende component.
Daarom de vector r van afmeting n met de beperking:
∑ (xik -
Hebben (n - 1) vrijheidsgraden.
Opnieuw wordt toegepast dat de berekening van het aantal vrijheidsgraden is:
vrijheidsgraden: = n (afmetingen) - 1 (beperkingen) = n-1
De variantie stwee wordt gedefinieerd als het gemiddelde van het kwadraat van de afwijkingen (of residuen) van de steekproef van n gegevens:
stwee rr) / (n-1)
waar r is de vector van de residuen r = (x1 -
stwee = ∑ (xik -
In elk geval moet worden opgemerkt dat bij het berekenen van het gemiddelde van het kwadraat van de residuen, het wordt gedeeld door (n-1) en niet door n, aangezien zoals besproken in de vorige paragraaf, het aantal vrijheidsgraden van de vector r is (n-1).
Als voor de berekening van de variantie werden gedeeld door n in plaats van (n-1), zou het resultaat een bias hebben die erg significant is voor waarden van n onder de 50.
In de literatuur komt de variantieformule ook voor met de deler n in plaats van (n-1), als het gaat om de variantie van een populatie.
Maar de verzameling van de willekeurige variabele van de residuen, vertegenwoordigd door de vector r, Hoewel het dimensie n heeft, heeft het alleen (n-1) vrijheidsgraden. Als het aantal gegevens echter groot genoeg is (n> 500), convergeren beide formules naar hetzelfde resultaat.
Rekenmachines en spreadsheets bieden beide versies van de variantie en de standaarddeviatie (de vierkantswortel van de variantie).
Onze aanbeveling, gezien de hier gepresenteerde analyse, is om altijd de versie met (n-1) te kiezen elke keer dat het nodig is om de variantie of standaarddeviatie te berekenen, om vertekende resultaten te voorkomen..
Sommige kansverdelingen in continue willekeurige variabele zijn afhankelijk van een parameter die wordt aangeroepen graad van vrijheid, is het geval van de Chi-kwadraatverdeling (χtwee.
De naam van deze parameter komt precies van de vrijheidsgraden van de onderliggende willekeurige vector waarop deze verdeling van toepassing is.
Stel dat we g-populaties hebben, waaruit monsters van grootte n worden genomen:
X1 = (x11, x1twee,… X1n
X2 = (x21, x2twee,… X2n
.
Xj = (xj1, xjtwee,… Xjn
.
Xg = (xg1, xgtwee,… Xgn
Een bevolking j wat heeft gemiddeld
De gestandaardiseerde of genormaliseerde variabele zjik is gedefinieerd als:
zjik = (xjik -
En de vector Zj wordt als volgt gedefinieerd:
Zj = (zj1, zjtwee,..., zjik,..., zjn) en volgt de gestandaardiseerde normale verdeling N (0,1).
Dus de variabele:
Q = ((z11 ^ 2 + z21^ 2 +…. + zg1^ 2), ...., (Z1n^ 2 + z2n^ 2 +…. + zgn^ 2))
volg de distributie χtwee(g) de chi-kwadraatverdeling met vrijheidsgraad g.
Als u hypothesen wilt testen op basis van een bepaalde set willekeurige gegevens, moet u de aantal vrijheidsgraden g de Chi-kwadraattoets kunnen toepassen.
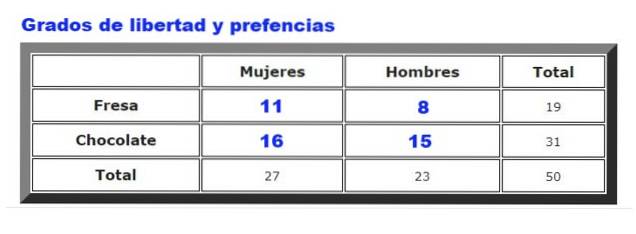
Als voorbeeld zullen de verzamelde gegevens over de voorkeuren van chocolade- of aardbeienijs bij mannen en vrouwen in een bepaalde ijssalon worden geanalyseerd. De frequentie waarmee mannen en vrouwen voor aardbei of chocolade kiezen, is samengevat in figuur 2.
Eerst wordt de tabel met verwachte frequenties berekend, die wordt opgesteld door de te vermenigvuldigen totaal aantal rijen voor hem totaal aantal kolommen, gedeeld door totale gegevens. Het resultaat wordt weergegeven in de volgende afbeelding:

Vervolgens gaan we verder met het berekenen van het Chi-kwadraat (uit de gegevens) met behulp van de volgende formule:
χtwee = ∑ (F.of - F.entwee / Fen
Waar Fof zijn de waargenomen frequenties (Figuur 2) en F.en zijn de verwachte frequenties (Figuur 3). De sommatie gaat over alle rijen en kolommen, die in ons voorbeeld vier termen opleveren.
Na het uitvoeren van de operaties krijgt u:
χtwee = 0,2043.
Nu is het nodig om te vergelijken met het theoretische Chi-kwadraat, dat afhangt van de aantal vrijheidsgraden g.
In ons geval wordt dit aantal als volgt bepaald:
g = (# rijen - 1) (# kolommen - 1) = (2-1) (2-1) = 1 * 1 = 1.
Het blijkt dat het aantal vrijheidsgraden g in dit voorbeeld 1 is.
Als je de nulhypothese (H0: er is geen correlatie tussen SMAAK en GESLACHT) wilt controleren of verwerpen met een significantieniveau van 1%, wordt de theoretische Chi-kwadraatwaarde berekend met vrijheidsgraad g = 1.
De waarde wordt gezocht die de geaccumuleerde frequentie (1 - 0,01) = 0,99 maakt, dat wil zeggen 99%. Deze waarde (die kan worden verkregen uit de tabellen) is 6,636.
Als de theoretische Chi groter is dan de berekende, wordt de nulhypothese geverifieerd.
Dat wil zeggen, met de verzamelde gegevens, Niet geobserveerd relatie tussen de variabelen SMAAK en GESLACHT.



Niemand heeft nog op dit artikel gereageerd.