De maten van variabiliteit, Ook wel spreidingsmetingen genoemd, het zijn statistische indicatoren die aangeven hoe ver of hoe ver de gegevens verwijderd zijn van het rekenkundig gemiddelde. Als de gegevens dicht bij het gemiddelde liggen, is de verdeling geconcentreerd, en als ze ver weg zijn, is het een schaarse verdeling..
Er zijn veel variabiliteitsmetingen, waaronder de bekendste:
Deze maatregelen vormen een aanvulling op de metingen van centrale tendens en zijn nodig om de verspreiding van de verkregen gegevens te begrijpen en er zoveel mogelijk informatie uit te halen..
Bereik of bereik meet de breedte van een gegevensset. Om de waarde ervan te bepalen, moet het verschil tussen de gegevens met de hoogste waarde xmax. hoogte en degene met de laagste waarde xmin
R = xmax. hoogte - Xmin
Als de gegevens niet los zijn maar gegroepeerd op interval, wordt het bereik berekend door het verschil tussen de bovengrens van het laatste interval en de ondergrens van het eerste interval.
Als het bereik een kleine waarde is, betekent dit dat alle gegevens redelijk dicht bij elkaar liggen, maar een groot bereik geeft aan dat er veel variabiliteit is. Het is duidelijk dat, afgezien van de bovengrens en de ondergrens van de gegevens, het bereik geen rekening houdt met de waarden ertussen, dus het wordt niet aanbevolen om het te gebruiken wanneer het aantal gegevens groot is.
Het is echter een onmiddellijke maat om te berekenen en heeft dezelfde eenheden van de gegevens, dus het is gemakkelijk te interpreteren.
Hieronder staat de lijst met het aantal gescoorde doelpunten tijdens het weekend in de voetbalcompetities van negen landen:
40, 32, 35, 36, 37, 31, 37, 29, 39
Dit is een niet-gegroepeerde dataset. Om het bereik te vinden, gaan we ze bestellen van laag naar hoog:
29, 31, 32, 35, 36, 37, 37, 39, 40
De gegevens met de hoogste waarde zijn 40 doelen en degene met de laagste waarde is 29 doelen, daarom is het bereik:
R = 40-29 = 11 doelpunten.
Er kan van worden uitgegaan dat het bereik klein is in vergelijking met de gegevens met de minimumwaarde, die 29 doelen zijn, dus kan worden aangenomen dat de gegevens geen grote variabiliteit hebben.
Deze maat voor variabiliteit wordt berekend door het gemiddelde van de absolute waarden van de afwijkingen ten opzichte van het gemiddelde.. Geeft de gemiddelde afwijking aan als DM., Voor niet-gegroepeerde gegevens wordt de gemiddelde afwijking berekend met behulp van de volgende formule:
Waar n het aantal beschikbare gegevens is, xik vertegenwoordigt elke gegevens en x ̄ is het gemiddelde, dat wordt bepaald door alle gegevens op te tellen en te delen door n:
De gemiddelde afwijking maakt het mogelijk om gemiddeld te weten in hoeveel eenheden de gegevens afwijken van het rekenkundig gemiddelde en heeft het voordeel dat ze dezelfde eenheden hebben als de gegevens waarmee we werken.
Op basis van de gegevens uit het bereikvoorbeeld is het aantal gescoorde doelpunten:
40, 32, 35, 36, 37, 31, 37, 29, 39
Als u de gemiddelde afwijking D wilt vindenM. Uit deze gegevens is het nodig om eerst het rekenkundig gemiddelde x† te berekenen:

En nu de waarde van x† bekend is, gaan we verder met het vinden van de gemiddelde afwijking DM.
= 2,99 ≈ 3 doelpunten
Daarom kan worden gesteld dat de gegevens gemiddeld ongeveer 3 doelen verwijderd zijn van het gemiddelde, wat 35 doelen is, en zoals opgemerkt, is het een veel nauwkeurigere maatstaf dan het bereik..
De gemiddelde afwijking is een veel fijnere maatstaf voor variabiliteit dan het bereik, maar aangezien het wordt berekend door de absolute waarde van de verschillen tussen elke gegevens en het gemiddelde, biedt het geen grotere veelzijdigheid vanuit algebraïsch oogpunt..
Om deze reden heeft de variantie de voorkeur, die overeenkomt met het gemiddelde van het kwadratische verschil van elke gegevens met het gemiddelde en wordt berekend met behulp van de formule:
In deze uitdrukking, stwee geeft de variantie aan, en zoals altijd xik vertegenwoordigt elk van de gegevens, x ̄ is het gemiddelde en n is de totale gegevens.
Als je met een steekproef werkt in plaats van met de populatie, wordt de variantie bij voorkeur als volgt berekend:
In elk geval wordt variantie gekenmerkt door altijd een positieve grootheid te zijn, maar aangezien het het gemiddelde is van de kwadratische verschillen, is het belangrijk op te merken dat het niet dezelfde eenheden heeft als die van de gegevens..
Om de variantie van de gegevens in de voorbeelden van bereik en gemiddelde afwijking te berekenen, gaan we verder met het vervangen van de overeenkomstige waarden en voeren we de aangegeven sommatie uit. In dit geval kiezen we ervoor om te delen door n-1:

= 13,86
De variantie heeft niet dezelfde eenheid als die van de variabele die wordt bestudeerd, als de gegevens bijvoorbeeld in meters komen, resulteert de variantie in vierkante meters. Of in het doelenvoorbeeld zou het in het kwadraat zijn, wat nergens op slaat.
Daarom wordt de standaarddeviatie gedefinieerd, ook wel typische afwijking, als de vierkantswortel van de variantie:
s = √stwee
Op deze manier wordt een maatstaf voor de variabiliteit van de gegevens verkregen in dezelfde eenheden als deze, en hoe lager de waarde van s, hoe meer gegroepeerd de gegevens rond het gemiddelde zijn..
Zowel de variantie als de standaarddeviatie zijn de variabiliteitsmetingen die moeten worden gekozen wanneer het rekenkundig gemiddelde de maat is van de centrale tendens die het gedrag van de gegevens het beste beschrijft..
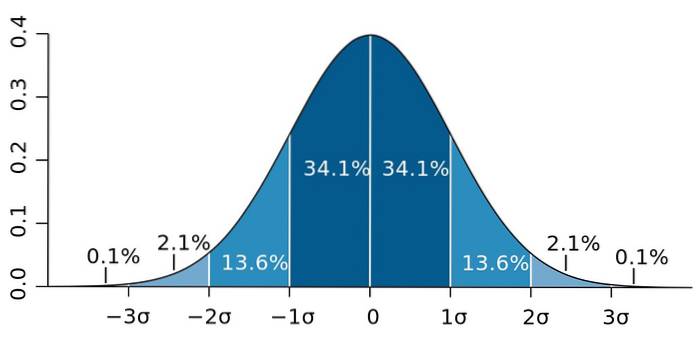
En het is dat de standaarddeviatie een belangrijke eigenschap heeft, bekend als de stelling van Chebyshev: ten minste 75% van de waarnemingen bevinden zich in het interval gedefinieerd door X ± 2 sec. Met andere woorden, 75% van de gegevens is maximaal 2 seconden verwijderd van het gemiddelde..
Evenzo ligt minstens 89% van de waarden op een afstand van 3s van het gemiddelde, een percentage dat kan worden uitgebreid, zolang er maar veel gegevens beschikbaar zijn en ze een normale verdeling volgen..
Figuur 2. - Als de gegevens een normale verdeling volgen, vallen 95,4 ervan binnen twee standaarddeviaties aan weerszijden van het gemiddelde. Bron: Wikimedia Commons.
De standaarddeviatie van de gegevens in de vorige voorbeelden is:
s = √stwee = √13,86 = 3,7 ≈ 4 doelpunten



Niemand heeft nog op dit artikel gereageerd.