
De trend maatregelen centraal ze geven de waarde aan waarrond de gegevens van een distributie zich bevinden. De bekendste is het gemiddelde of rekenkundig gemiddelde, dat bestaat uit het optellen van alle waarden en het resultaat delen door het totale aantal gegevens.
Als de verdeling echter uit een groot aantal waarden bestaat en ze niet op een geordende manier worden gepresenteerd, is het niet eenvoudig om de nodige berekeningen uit te voeren om de waardevolle informatie die ze bevatten te extraheren..

Daarom zijn ze gegroepeerd in klassen of categorieën om een distributie van frequenties. Door deze eerdere ordening van de gegevens uit te voeren, is het gemakkelijker om de maten van centrale tendens te berekenen, waaronder:
-Voor de helft
-Mediaan
-mode
-Geometrisch gemiddelde
-Harmonisch gemiddelde
Hier zijn de formules voor de metingen van centrale tendens voor de gegroepeerde gegevens:
Het gemiddelde wordt het meest gebruikt om kwantitatieve gegevens (numerieke waarden) te karakteriseren, hoewel het vrij gevoelig is voor de extreme waarden van de verdeling. Het wordt berekend door:
Met:
-X: gemiddelde of rekenkundig gemiddelde
-F.ik: klasse frequentie
-mik: het klassenteken
-g: aantal klassen
-n: totale gegevens
Om het te berekenen, is het nodig om het interval te vinden dat de waarneming n / 2 bevat en te interpoleren om de numerieke waarde van die waarneming te bepalen, met behulp van de volgende formule:
Waar:
-c: breedte van het interval waartoe de mediaan behoort
-B.M.: ondergrens van genoemd interval
-F.m: aantal waarnemingen in het interval
-n / 2: totale gegevens gedeeld door 2.
-F.BM: aantal waarnemingen voordat van het interval dat de mediaan bevat.
Daarom is de mediaan een maatstaf voor de positie, dat wil zeggen dat het de gegevensset in twee delen verdeelt. Ze kunnen ook worden gedefinieerd kwartielen, decielen Y percentielen, die de verdeling verdelen in respectievelijk vier, tien en honderd delen.
In de gepoolde gegevens wordt de klasse of categorie met de meeste waarnemingen doorzocht. Dit is de modale klasse. Een distributie kan twee of meer modi hebben, in welk geval deze wordt aangeroepen bimodaal Y multimodaal, respectievelijk.
U kunt de modus ook in gegroepeerde gegevens berekenen volgens de vergelijking:
Met:
-L.1: ondergrens van de klasse waarin de modus wordt gevonden
-Δ1: trek af tussen de frequentie van de modale klasse en de frequentie van de klasse die eraan voorafgaat.
-Δtwee: aftrekken tussen de frequentie van de modale klasse en de frequentie van de volgende klasse.
-c: breedte van het interval dat de modus bevat
Het harmonische gemiddelde wordt aangegeven met H. Als je een set hebt van n x waarden1, Xtwee, X3..., het harmonische gemiddelde is het omgekeerde of omgekeerde van het rekenkundig gemiddelde van de inverse waarden.
Het is gemakkelijker om het door de formule te zien:
En als de gegroepeerde gegevens beschikbaar zijn, wordt de uitdrukking:
Waar:
-H: harmonisch gemiddelde
-F.ik: klasse frequentie
-mik: klassecijfer
-g: aantal klassen
-N = f1 + F.twee + F.3 +
Als ze hebben n positieve getallen x1, Xtwee, X3..., Zijn geometrisch gemiddelde G wordt berekend door de n-de wortel van het product van alle getallen:
In het geval van gegroepeerde gegevens kan worden aangetoond dat de decimale logaritme van de geometrisch gemiddelde log G wordt gegeven door:
Waar:
-G: geometrisch gemiddelde
-F.ik: klasse frequentie
-mik: het klassenteken
-g: aantal klassen
-N = f1 + F.twee + F.3 +
Het is altijd waar dat:
H ≤ G ≤ X
De volgende definities zijn vereist om de waarden te vinden die in de bovenstaande formules worden beschreven:
Frequentie wordt gedefinieerd als het aantal keren dat een gegevensstuk wordt herhaald.
Het is het verschil tussen de hoogste en laagste waarden, aanwezig in de verdeling.
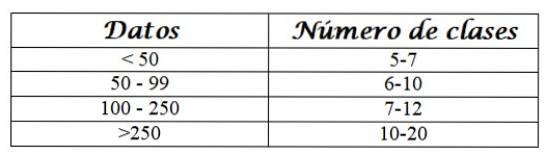
Om te weten in hoeveel klassen we de gegevens groeperen, gebruiken we enkele criteria, bijvoorbeeld de volgende:
De extreme waarden van elke klasse of interval worden aangeroepen limieten en elke klasse kan zowel goed gedefinieerde limieten hebben, in welk geval het een lagere en een hogere limiet heeft. Of het kan open limieten hebben, wanneer een bereik wordt gegeven, bijvoorbeeld waarden groter of kleiner dan een bepaald getal.
Het bestaat simpelweg uit het middelpunt van het interval en wordt berekend door de bovengrens en de ondergrens te middelen.
De gegevens kunnen worden gegroepeerd in klassen van gelijke of verschillende grootte, dit is de breedte of breedte. De eerste optie wordt het meest gebruikt, omdat het berekeningen veel gemakkelijker maakt, hoewel het in sommige gevallen noodzakelijk is dat de klassen verschillende breedtes hebben.
De breedte c Het interval kan worden bepaald door de volgende formule:
c = Bereik / Nc
Waarc is het aantal klassen.
Hieronder hebben we een reeks snelheidsmetingen in km / u, genomen met radar, die overeenkomen met 50 auto's die door een straat in een bepaalde stad reden:
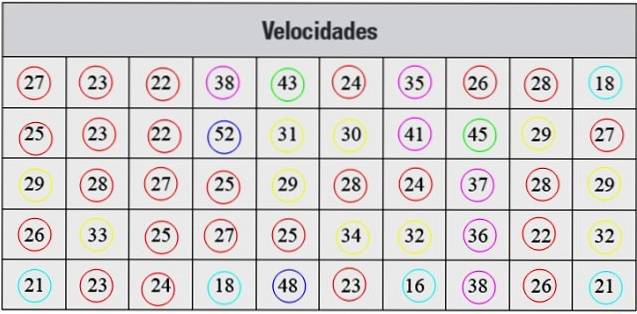
De gegevens die op deze manier worden gepresenteerd, zijn niet georganiseerd, dus de eerste stap is om deze in klassen te groeperen.
Vind het bereik R:
R = (52 - 16) km / u = 36 km / u
Selecteer het aantal klassen Nc, volgens de gegeven criteria. Aangezien er 50 gegevens zijn, kunnen we N kiezenc = 6.
Bereken de breedte c van het interval:
c = Bereik / Nc = 36/6 = 6
Vorm klassen en groepsgegevens als volgt: voor de eerste klasse wordt als ondergrens een waarde gekozen die iets kleiner is dan de laagste waarde in de tabel, daarna wordt de eerder berekende waarde van c = 6 bij deze waarde opgeteld, dus behaalt de bovengrens van de eerste klasse.
We gaan op dezelfde manier te werk om de rest van de klassen te bouwen, zoals weergegeven in de volgende tabel:
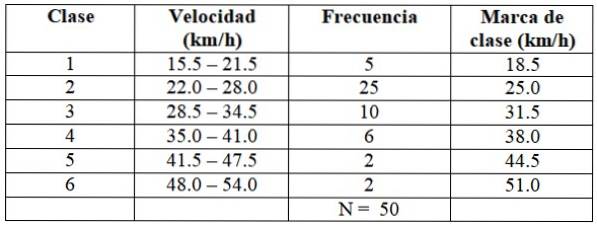
Elke frequentie correspondeert met een kleur in figuur 2, op deze manier wordt er voor gezorgd dat er geen waarde ontsnapt aan de telling..
X = (5 x 18,5 +25 x 25,0 + 10 x 31,5 + 6 x 38,0 + 2 x 44,5 + 2 x 51,0) ÷ 50 = 29,03 km / u
De mediaan is in klasse 2 van de tabel, aangezien er de eerste 30 gegevens van de verdeling zijn.
-Breedte van het interval waartoe de mediaan behoort: c = 6
-Ondergrens van het interval waarbij de mediaan is: BM. = 22,0 km / u
-Aantal waarnemingen dat het interval f bevatm = 25
-Totale gegevens gedeeld door 2: 50/2 = 25
-Aantal waarnemingen zijn er voordat van het interval met de mediaan: fBM = 5
En de operatie is:
Mediaan = 22,0 + [(25-5) ÷ 25] x 6 = 26,80 km / u
Mode zit ook in klasse 2:
-Intervalbreedte: c = 6
-Ondergrens van de klasse waarin de modus wordt gevonden: L1 = 22,0
-Trek af tussen de frequentie van de modale klasse en de frequentie van de klasse die eraan voorafgaat: Δ1 = 25-5 = 20
-Trek af tussen de frequentie van de modale klasse en de frequentie van de volgende klasse: Δtwee = 25 - 10 = 15
Met deze gegevens is de operatie:
Modus = 22,0 + [20 ÷ (20 + 15)] x6 = 25,4 km / u
N = f1 + F.twee + F.3 +… = 50
logboek G = (5 x logboek 18,5 + 25 x logboek 25 + 10 x logboek 31,5 + 6 x logboek 38 + 2 × logboek 44,5 + 2 x logboek 51) / 50 =
log G = 1.44916053
G = 28,13 km / uur
1 / H = (1/50) x [(5 / 18,5) + (25/25) + (10 / 31,5) + (6/38) + (2 / 44,5) + (2/51)] = 0,0366
H = 27,32 km / uur
De eenheden van de variabelen zijn km / u:
-Gemiddeld: 29.03
-Mediaan: 26,80
-Mode: 25.40
-Geometrisch gemiddelde: 28,13
-Harmonisch gemiddelde: 27.32


Niemand heeft nog op dit artikel gereageerd.