De niet-gegroepeerde gegevens zijn die welke, verkregen uit een studie, nog niet per klas zijn georganiseerd. Als het een beheersbaar aantal gegevens is, meestal 20 of minder, en er zijn weinig verschillende gegevens, kan het worden behandeld als niet-gegroepeerde en waardevolle informatie die eruit wordt gehaald.
De niet-gegroepeerde gegevens komen zoals ze zijn uit de enquête of de studie die is uitgevoerd om ze te verkrijgen en missen daarom verwerking. Laten we eens kijken naar enkele voorbeelden:

-Resultaten van een IQ-test op 20 willekeurige studenten van een universiteit. De verkregen gegevens waren de volgende:
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112,106
-Leeftijd van 20 werknemers van een bepaalde populaire coffeeshop:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 21, 19, 22, 27, 29, 23, 20
-Het eindcijfergemiddelde van 10 leerlingen in een wiskundeklas:
3,2; 3.1; 2,4; 4,0; 3,5; 3.0; 3,5; 3.8; 4.2; 4.9
Artikel index
Er zijn drie belangrijke eigenschappen die een set statistische gegevens karakteriseren, of ze nu gegroepeerd zijn of niet, namelijk:
-Positie, dat is de neiging van de gegevens om rond bepaalde waarden te clusteren.
-Spreiding, een indicatie van hoe verspreid of verspreid de gegevens zijn rond een bepaalde waarde.
-Vorm, Het verwijst naar de manier waarop de gegevens worden gedistribueerd, wat wordt gewaardeerd wanneer een grafiek hiervan wordt geconstrueerd. Er zijn zeer symmetrische curven en ook scheef, ofwel naar links of naar rechts van een bepaalde centrale waarde.
Voor elk van deze eigenschappen is er een reeks maatregelen die ze beschrijven. Eenmaal verkregen, geven ze ons een overzicht van het gedrag van de gegevens:
-De meest gebruikte positiematen zijn het rekenkundig gemiddelde of gewoon het gemiddelde, de mediaan en de modus.
-Bereik, variantie en standaarddeviatie worden vaak gebruikt bij spreiding, maar het zijn niet de enige maatstaven voor spreiding..
-En om de vorm te bepalen, worden het gemiddelde en de mediaan vergeleken door middel van bias, zoals je binnenkort zult zien.
-Het rekenkundig gemiddelde, ook wel bekend als gemiddelde en aangeduid als X, wordt het als volgt berekend:
X = (x1 + Xtwee + X3 +… Xn) / n
Waar x1, Xtwee,Xn, zijn de gegevens en n is het totaal ervan. In sommatie hebben we:
-Mediaan is de waarde die verschijnt in het midden van een geordende reeks gegevens, dus om deze te verkrijgen, is het noodzakelijk om eerst de gegevens te ordenen.
Als het aantal waarnemingen oneven is, is het geen probleem om het middelpunt van de verzameling te vinden, maar als we een even aantal gegevens hebben, worden de twee centrale gegevens doorzocht en gemiddeld.
-Mode is de meest voorkomende waarde die wordt waargenomen in de dataset. Het bestaat niet altijd, aangezien het mogelijk is dat geen enkele waarde vaker wordt herhaald dan een andere. Er kunnen ook twee gegevens zijn met gelijke frequentie, in dat geval spreken we van een bimodale verdeling.
In tegenstelling tot de vorige twee metingen, kan de modus worden gebruikt met kwalitatieve gegevens.
Laten we eens kijken hoe deze positiematen worden berekend met een voorbeeld:
Stel dat we het rekenkundig gemiddelde, de mediaan en de modus willen bepalen in het aan het begin voorgestelde voorbeeld: de leeftijd van 20 werknemers van een cafetaria:
24, 20, 22, 19, 18, 27, 25, 19, 27, 18, 21, 22, 23, 21, 19, 22, 27, 29, 23, 20
De voor de helft het wordt eenvoudig berekend door alle waarden op te tellen en te delen door n = 20, het totale aantal gegevens. Op deze manier:
X = (24 + 20 + 22 + 19 + 18 + 27+ 25 + 19 + 27 + 18 + 21 + 22 + 23 + 21+ 19 + 22 + 27+ 29 + 23+ 20) / 20 =
= 22,3 jaar.
Om het mediaan- je moet de dataset eerst sorteren:
18, 18, 19, 19, 19, 20, 20, 21, 21, 22, 22, 22, 23, 23, 24, 25, 27, 27, 27, 29
Omdat het een even aantal gegevens is, worden de twee centrale gegevens, die vetgedrukt zijn gemarkeerd, genomen en gemiddeld. Omdat ze allebei 22 zijn, is de mediaan 22 jaar.
eindelijk, de mode Het zijn de gegevens die het meest worden herhaald of degene waarvan de frequentie hoger is, namelijk 22 jaar.
Het bereik is gewoon het verschil tussen de grootste en de kleinste van de gegevens en stelt u in staat snel de variabiliteit van de gegevens te beoordelen. Maar afgezien daarvan zijn er andere dispersiemaatstaven die meer informatie bieden over de distributie van de gegevens..
De variantie wordt aangeduid als s en wordt berekend met de uitdrukking:
Dus om de resultaten correct te interpreteren, wordt de standaarddeviatie gedefinieerd als de vierkantswortel van de variantie, of ook de quasi-standaarddeviatie, de vierkantswortel van de quasi-variantie:
Het is de vergelijking tussen de gemiddelde X en de mediaan Med:
-Als Med = gemiddelde X: de gegevens zijn symmetrisch.
-Wanneer X> Med: naar rechts scheeftrekken.
-En als X < Med: los datos sesgan hacia la izquierda.
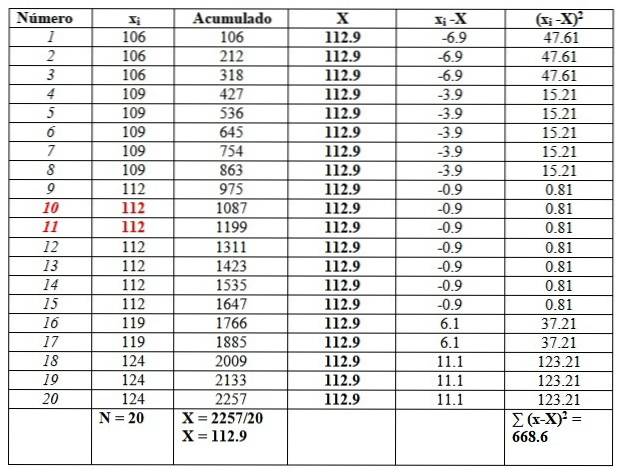
Vind gemiddelde, mediaan, modus, bereik, variantie, standaarddeviatie en bias voor de resultaten van een IQ-test uitgevoerd op 20 studenten van een universiteit:
119, 109, 124, 119, 106, 112, 112, 112, 112, 109, 112, 124, 109, 109, 109, 106, 124, 112, 112, 106
We zullen de gegevens ordenen, omdat het nodig zal zijn om de mediaan te vinden.
106, 106, 106, 109, 109, 109, 109, 109, 112, 112, 112, 112, 112, 112, 112, 119, 119, 124, 124, 124
En we zullen ze als volgt in een tabel plaatsen om de berekeningen te vergemakkelijken. De tweede kolom met de titel "Geaccumuleerd" is de som van de overeenkomstige gegevens plus de vorige..
Deze kolom helpt om gemakkelijk het gemiddelde te vinden, door de laatste geaccumuleerde gegevens te delen door het totale aantal gegevens, zoals te zien aan het einde van de kolom 'Geaccumuleerd':
X = 112,9
De mediaan is het gemiddelde van de centrale gegevens die rood zijn gemarkeerd: het cijfer 10 en het cijfer 11. Omdat ze hetzelfde zijn, is de mediaan 112.
Ten slotte is de modus de waarde die het meest wordt herhaald en is 112, met 7 herhalingen..
Met betrekking tot de spreidingsmaten is het bereik:
124-106 = 18.
De variantie wordt verkregen door het eindresultaat in de rechterkolom te delen door n:
s = 668,6 / 20 = 33,42
In dit geval is de standaarddeviatie de vierkantswortel van de variantie: √33,42 = 5,8.
Aan de andere kant zijn de waarden van de quasi-variantie en de quasi-standaarddeviatie:
sc= 668,6 / 19 = 35,2
Quasi-standaarddeviatie = √35,2 = 5,9
Ten slotte is de bias iets naar rechts, aangezien de gemiddelde 112,9 groter is dan de mediaan 112.



Niemand heeft nog op dit artikel gereageerd.