De standaardfout van schatting meet de afwijking in de waarde van een steekproefpopulatie. Dat wil zeggen, de standaardfout van de schatting meet de mogelijke variaties van het steekproefgemiddelde ten opzichte van de werkelijke waarde van het populatiegemiddelde..
Als u bijvoorbeeld de gemiddelde leeftijd van de bevolking van een land wilt weten (populatiegemiddelde), neemt u een kleine groep inwoners, die we een "steekproef" zullen noemen. Hieruit wordt de gemiddelde leeftijd (steekproefgemiddelde) geëxtraheerd en wordt aangenomen dat de populatie die gemiddelde leeftijd heeft met een standaardschattingsfout die min of meer varieert.
Opgemerkt moet worden dat het belangrijk is om de standaarddeviatie niet te verwarren met de standaardfout en met de standaardschattingsfout:
1- De standaarddeviatie is een maat voor de spreiding van de gegevens; dat wil zeggen, het is een maat voor de variabiliteit van de populatie.
2- De standaardfout is een maat voor de variabiliteit van de steekproef, berekend op basis van de standaarddeviatie van de populatie.
3- De standaardschattingsfout is een maat voor de fout die wordt gemaakt wanneer het steekproefgemiddelde wordt genomen als een schatting van het populatiegemiddelde.
Artikel index
De standaardschattingsfout kan worden berekend voor alle metingen die in de steekproeven worden verkregen (bijvoorbeeld standaardschattingsfout van het gemiddelde of standaardschattingsfout van de standaarddeviatie) en meet de fout die wordt gemaakt bij het schatten van de werkelijke populatie af te meten op basis van de steekproefwaarde
Uit de standaardschattingsfout wordt het betrouwbaarheidsinterval van de overeenkomstige maat geconstrueerd.
De algemene structuur van een formule voor de standaardschattingsfout is als volgt:
Standaardschattingsfout = ± Betrouwbaarheidscoëfficiënt * Standaardfout
Betrouwbaarheidscoëfficiënt = grenswaarde van een steekproefstatistiek of steekproefverdeling (onder andere normale of Gaussiaanse klok, Student's t) voor een bepaald waarschijnlijkheidsinterval.
Standaardfout = standaarddeviatie van de populatie gedeeld door de vierkantswortel van de steekproefomvang.
De betrouwbaarheidscoëfficiënt geeft het aantal standaardfouten aan dat u bereid bent toe te voegen aan en af te trekken van de meting om een zeker niveau van vertrouwen in de resultaten te hebben..
Stel dat u probeert een schatting te maken van het aandeel van de mensen in de populatie met gedrag A, en u wilt 95% vertrouwen hebben in uw resultaten..
Een steekproef van n mensen wordt genomen en de steekproefverhouding p en zijn complement q worden bepaald.
Standaardfout van schatting (SEE) = ± Betrouwbaarheidscoëfficiënt * Standaardfout
Betrouwbaarheidscoëfficiënt = z = 1,96.
Standaardfout = de vierkantswortel van de verhouding tussen het product van de steekproefverhouding en zijn complement en de steekproefomvang n.
Aan de hand van de standaardschattingsfout wordt het interval bepaald waarin het populatie-aandeel naar verwachting wordt gevonden of het steekproefaandeel van andere steekproeven die uit die populatie kunnen worden gevormd, met een betrouwbaarheidsniveau van 95%:
p - EEE ≤ Bevolkingsaandeel ≤ p + EEE
1- Stel dat u probeert een schatting te maken van het percentage mensen in de bevolking dat een voorkeur heeft voor een verrijkte melkformule, en dat u 95% vertrouwen wilt hebben in uw resultaten..
Er wordt een steekproef van 800 mensen genomen en 560 mensen in de steekproef zijn vastbesloten een voorkeur te hebben voor verrijkte melkvoeding. Bepaal een interval waarin het populatie-aandeel en het aandeel van andere monsters die uit de populatie kunnen worden genomen, naar verwachting worden gevonden, met een betrouwbaarheid van 95%
a) Laten we de steekproefverhouding p en zijn complement berekenen:
p = 560/800 = 0,70
q = 1 - p = 1 - 0,70 = 0,30
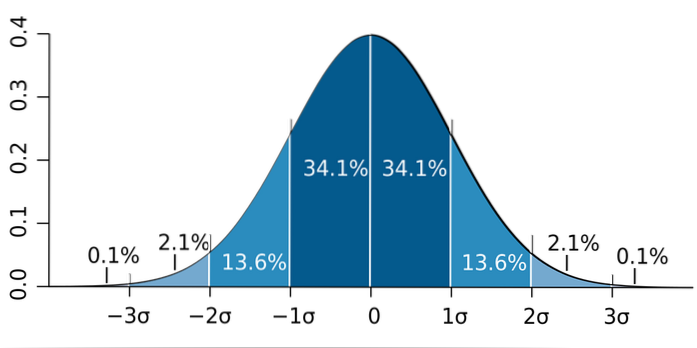
b) Het is bekend dat het aandeel een normale verdeling over grote monsters benadert (groter dan 30). Vervolgens wordt de zogenaamde regel 68 - 95 - 99,7 toegepast en moeten we:
Betrouwbaarheidscoëfficiënt = z = 1,96
Standaardfout = √ (p * q / n)
Standaardfout van schatting (SEE) = ± (1,96) * √ (0,70) * (0,30) / 800) = ± 0,0318
c) Op basis van de standaardschattingsfout wordt het interval bepaald waarin het populatie-aandeel met een betrouwbaarheidsniveau van 95% naar verwachting wordt gevonden:
0,70 - 0,0318 ≤ Bevolkingsaandeel ≤ 0,70 + 0,0318
0,6682 ≤ Bevolkingsaandeel ≤ 0,7318
Het aandeel van de steekproef van 70% zal naar verwachting met maar liefst 3,18 procentpunten veranderen als u een andere steekproef van 800 personen neemt of als het werkelijke populatie-aandeel tussen 70 - 3,18 = 66,82% en 70 + 3,18 = 73,18% ligt..
2- We nemen uit Spiegel en Stephens, 2008, de volgende casestudy:
Uit het totaal van de wiskundecijfers van de eerstejaarsstudenten van een universiteit is een willekeurige steekproef van 50 cijfers genomen, waarbij het gemiddelde gevonden werd op 75 punten en de standaarddeviatie op 10 punten. Wat zijn de 95% -betrouwbaarheidsgrenzen voor het schatten van de gemiddelde wiskundecijfers van de universiteit??
a) Laten we de standaardschattingsfout berekenen:
95% betrouwbaarheidscoëfficiënt = z = 1,96
Standaardfout = s / √n
Standaardfout van schatting (SEE) = ± (1,96) * (10√50) = ± 2,7718
b) Uit de standaardschattingsfout wordt het interval bepaald waarin het populatiegemiddelde of het gemiddelde van een andere steekproef van grootte 50 naar verwachting wordt gevonden, met een betrouwbaarheidsniveau van 95%:
50 - 2.7718 ≤ Bevolkingsgemiddelde ≤ 50 + 2.7718
47,2282 ≤ Bevolkingsgemiddelde ≤ 52,7718
c) Het gemiddelde van de steekproef zal naar verwachting met maar liefst 2,7718 punten veranderen als een andere steekproef van 50 cijfers wordt genomen of als de feitelijke gemiddelde wiskundecijfers van de universitaire populatie tussen 47.2282 punten en 52.7718 punten liggen..
Niemand heeft nog op dit artikel gereageerd.