De Absolute frequentie Het wordt gedefinieerd als het aantal keren dat dezelfde gegevens worden herhaald binnen de set waarnemingen van een numerieke variabele. De som van alle absolute frequenties is gelijk aan het totaal van de gegevens.
Als u veel waarden van een statistische variabele heeft, is het handig om ze op de juiste manier te ordenen om informatie over zijn gedrag te extraheren. Dergelijke informatie wordt gegeven door de maten van centrale neiging en de maten van spreiding..
Bij de berekeningen van deze metingen worden de gegevens weergegeven door de frequentie waarmee ze in alle waarnemingen voorkomen..
Het volgende voorbeeld laat zien hoe onthullend de absolute frequentie van elk gegeven is. In de eerste helft van mei waren dit de best verkochte cocktailjurkmaten van een bekende dameskledingwinkel:
8; 10; 8; 4; 6; 10; 12; 14; 12; 16; 8; 10; 10; 12; 6; 6; 4; 8; 12; 12; 14; 16; 18; 12; 14; 6; 4; 10; 10; 18
Hoeveel jurken worden er in een bepaalde maat verkocht, bijvoorbeeld maat 10? Eigenaren zijn geïnteresseerd in het weten om te bestellen.
Het ordenen van de gegevens maakt het gemakkelijker om te tellen, er zijn in totaal precies 30 waarnemingen, die als volgt zijn gerangschikt van de kleinste naar de grootste grootte:
4; 4; 4; 6; 6; 6; 6; 8; 8; 8; 8; 10 10 10 10 10 1012; 12; 12; 12; 12; 12; 14; 14; 14; 16; 16; 18; 18
En nu is het duidelijk dat maat 10 6 keer wordt herhaald, daarom is de absolute frequentie gelijk aan 6. Dezelfde procedure wordt uitgevoerd om de absolute frequentie van de overige maten te achterhalen..
Artikel index
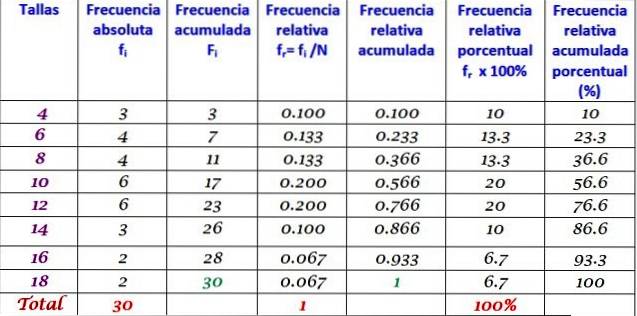
De absolute frequentie, aangeduid als fik, is gelijk aan het aantal keren dat een bepaalde waarde Xik valt binnen de groep waarnemingen.
Ervan uitgaande dat het totaal van de waarnemingen N-waarden zijn, moet de som van alle absolute frequenties gelijk zijn aan dit aantal:
∑fik = f1 + F.twee + F.3 +... fn = N
Als elke waarde van fik gedeeld door het totale aantal gegevens N, hebben we de relatieve frequentie F.r van de X-waardeik
F.r = fik / N
Relatieve frequenties zijn waarden tussen 0 en 1, omdat N altijd groter is dan elke fik, maar de som moet gelijk zijn aan 1.
Elke waarde van f vermenigvuldigen met 100r jij hebt de percentage relatieve frequentie, waarvan de som 100% is:
Percentage relatieve frequentie = (fik / N) x 100%
Ook belangrijk is cumulatieve frequentie F.ik tot een bepaalde waarneming is dit de som van alle absolute frequenties tot en met die waarneming:
F.ik = f1 + F.twee + F.3 +... fik
Als de verzamelde frequentie wordt gedeeld door het totale aantal gegevens N, hebben we de cumulatieve relatieve frequentie, die vermenigvuldigd met 100 geeft de percentage cumulatieve relatieve frequentie.
Om de absolute frequentie te vinden van een bepaalde waarde die bij een gegevensset hoort, worden ze allemaal georganiseerd van laag naar hoog en wordt het aantal keren dat de waarde verschijnt geteld.
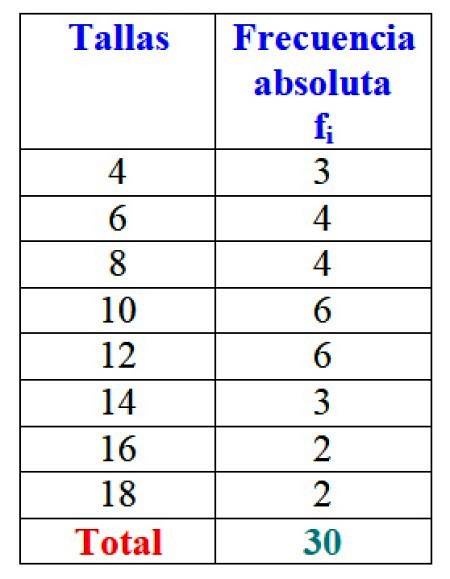
In het voorbeeld van kledingmaten is de absolute frequentie van maat 4 3 jurken, dat wil zeggen f1 = 3. Voor maat 6 werden 4 jurken verkocht: ftwee = 4. In maat 8 werden ook 4 jurken verkocht, f3 = 4 enzovoort.
De totale resultaten kunnen worden weergegeven in een tabel met de absolute frequenties van elk:
Uiteraard is het voordelig om de informatie te ordenen en in één oogopslag te kunnen raadplegen, in plaats van te werken met individuele gegevens.
Belangrijk: merk op dat bij het optellen van alle waarden van kolom fik u krijgt altijd het totale aantal gegevens. Als dit niet het geval is, moet u de boekhouding controleren, aangezien er een fout is opgetreden.
De bovenstaande tabel kan worden uitgebreid door de andere frequentietypen in opeenvolgende kolommen aan de rechterkant toe te voegen:
De frequentieverdeling is het resultaat van het organiseren van de gegevens in termen van hun frequenties. Wanneer u met veel gegevens werkt, is het handig om ze te groeperen in categorieën, intervallen of klassen, elk met zijn respectieve frequenties: absoluut, relatief, geaccumuleerd en percentage..
Het doel hiervan is om gemakkelijker toegang te krijgen tot de informatie in de gegevens en om ze correct te interpreteren, wat niet mogelijk is wanneer ze niet in volgorde worden gepresenteerd..
In het voorbeeld van formaten zijn de gegevens niet gegroepeerd omdat het niet te veel formaten zijn en gemakkelijk kunnen worden gemanipuleerd en verantwoord. Kwalitatieve variabelen kunnen ook op deze manier worden bewerkt, maar wanneer de gegevens erg talrijk zijn, is het beter om te werken door ze in klassen te groeperen.
Houd rekening met het volgende om uw gegevens in klassen van gelijke grootte te groeperen:
-Klasse grootte, breedte of breedte: is het verschil tussen de hoogste waarde in de klas en de laagste.
De grootte van de klas wordt bepaald door de rang R te delen door het aantal te overwegen klassen. Het bereik is het verschil tussen de maximale waarde van de gegevens en de kleinste, als volgt:
Klasse grootte = rang / aantal klassen.
-Klasse limiet: interval van de ondergrens tot de bovengrens van de klas.
-Klasse cijfer: is het middelpunt van het interval, dat als representatief voor de klasse wordt beschouwd. Het wordt berekend met de halve som van de bovengrens en de ondergrens van de klasse.
-Aantal lessen: Sturges-formule kan worden gebruikt:
Aantal klassen = 1 + 3.322 log N
Waar N het aantal klassen is. Omdat het meestal een decimaal getal is, wordt het afgerond op het volgende gehele getal.
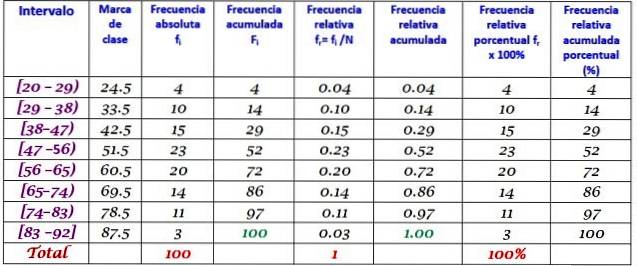
Een machine in een grote fabriek valt uit door terugkerende storingen. De opeenvolgende perioden van inactiviteit in minuten van genoemde machine worden hieronder geregistreerd, met in totaal 100 gegevens:
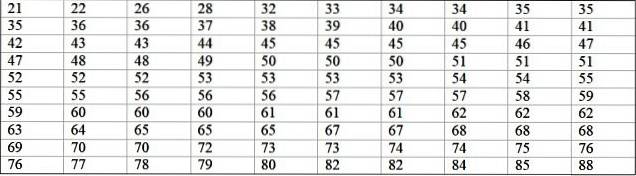
Eerst wordt het aantal klassen bepaald:
Aantal klassen = 1 + 3.322 log N = 1 + 3.32 log 100 = 7,64 ≈ 8
Klasseomvang = Bereik / Aantal klassen = (88-21) / 8 = 8.375
Het is ook een decimaal getal, dus 9 wordt genomen als de klasgrootte.
Het klassencijfer is het gemiddelde tussen de boven- en ondergrenzen van de klas, bijvoorbeeld voor klasse [20-29) is er een cijfer van:
Klassecijfer = (29 + 20) / 2 = 24,5
We gaan op dezelfde manier te werk om de klassemarkeringen van de resterende intervallen te vinden.
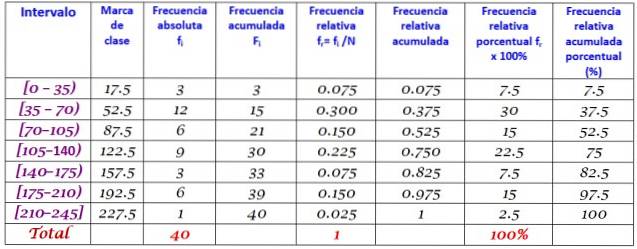
40 jongeren gaven aan dat de tijd in minuten die ze afgelopen zondag op internet doorbrachten, in oplopende volgorde als volgt was:
0; 12; twintig; 35; 35; 38; 40; Vier vijf; 45, 45; 59; 55; 58; 65; 65; 70; 72; 90; 95; 100; 100; 110; 110; 110; 120; 125; 125; 130; 130; 130; 150; 160; 170; 175; 180; 185; 190; 195; 200; 220.
Er wordt gevraagd om de frequentieverdeling van deze gegevens te construeren.
Het bereik R van de set van N = 40 gegevens is:
R = 220 - 0 = 220
Het toepassen van de Sturges-formule om het aantal klassen te bepalen, levert het volgende resultaat op:
Aantal klassen = 1 + 3.322 log N = 1 + 3.32 log 40 = 6.3
Omdat het een decimaal is, is het onmiddellijke gehele getal 7, daarom zijn de gegevens gegroepeerd in 7 klassen. Elke klasse heeft een breedte van:
Klasseomvang = Rang / Aantal klassen = 220/7 = 31.4
Een close en round waarde is 35, daarom wordt een klassebreedte van 35 gekozen.
Klassencijfers worden berekend door het gemiddelde te nemen van de boven- en ondergrenzen van elk interval, bijvoorbeeld voor het interval [0,35):
Klassecijfer = (0 + 35) / 2 = 17,5
Ga op dezelfde manier te werk met de andere klassen.
Ten slotte worden de frequenties berekend volgens de hierboven beschreven procedure, wat resulteert in de volgende verdeling:



Niemand heeft nog op dit artikel gereageerd.